In the previous lesson, we introduced the mathematical foundation of Graph Convolutional Networks (GCNs). You can find the explanation of the GCN formula in the following link: [link below].
Now, we will implement a GCN model in PyTorch, applying the concepts we learned. We will:
✅ Compute the degree matrix D.
✅ Compute the normalized adjacency matrix A-hat.
✅ Implement a GCN layer.
✅ Build a simple GCN model with two layers.
The core operation in GCNs follows this formula:
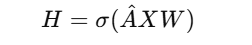
where:
- A-hat (A^) is the normalized adjacency matrix.
- X is the input feature matrix.
- W is the learnable weight matrix.
- H is the output after applying the graph convolution operation.
- σ(sigma) is the activation function (e.g., ReLU).
Let’s implement this step by step:
Let’s implement this step by step:
import torch
import torch.nn.functional as F
def compute_degree_matrix(A):
"""Computes the degree matrix D from adjacency matrix A."""
degrees = torch.sum(A, dim=1)
D = torch.diag(degrees)
return D
def normalize_adjacency(A):
"""Computes the normalized adjacency matrix A_hat = D^(-1/2) * A * D^(-1/2)."""
D = compute_degree_matrix(A)
D_inv_sqrt = torch.diag(torch.pow(torch.diag(D), -0.5))
A_hat = D_inv_sqrt @ A @ D_inv_sqrt
return A_hat
A. Computing the Degree Matrix (D)
The degree matrix (D) is a diagonal matrix where each diagonal element represents the sum of connections (or edges) for each node in the adjacency matrix.
Mathematically, if A is the adjacency matrix, the degree matrix D is computed as:

This means that each diagonal element of D contains the total number of edges connected to a given node.
Code Explanation:
- torch.sum(A, dim=1): Summing along axis=1 (rows) gives the degree of each node.
- torch.diag(degrees): Converts this degree vector into a diagonal matrix.
B. Computing the Normalized Adjacency Matrix (A^)
To stabilize training and ensure proper feature propagation, we normalize the adjacency matrix A. The normalized adjacency matrix A^ is computed as:

This normalization ensures that information is distributed more evenly across nodes.
class GCNLayer(torch.nn.Module):
def __init__(self, in_features, out_features):
super(GCNLayer, self).__init__()
self.W = torch.nn.Parameter(torch.randn(in_features, out_features)) # Learnable weights
def forward(self, A, X):
A_hat = normalize_adjacency(A) # Compute A_hat
H = A_hat @ X @ self.W # Graph convolution operation
return F.relu(H) # Apply ReLU activationCode Explanation:
- Define a weight matrix self.W that will be learned during training.
- Compute the normalized adjacency matrix A_hat using the function we defined earlier.
- Multiply A_hat @ X @ W to perform the graph convolution operation.
- Apply ReLU activation function to introduce non-linearity.
2. Defining the GCN Model
A GCN model consists of multiple layers stacked on top of each other. Each layer extracts higher-level node representations.
Here, we define a two-layer GCN:
- The first layer transforms input features into a hidden representation.
- The second layer maps hidden representations to output features.
class GCN(torch.nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super(GCN, self).__init__()
self.gcn1 = GCNLayer(input_dim, hidden_dim)
self.gcn2 = GCNLayer(hidden_dim, output_dim)
def forward(self, A, X):
H1 = self.gcn1(A, X) # First GCN layer
H2 = self.gcn2(A, H1) # Second GCN layer
return H2Explanation:
- First layer (gcn1) maps input features to a hidden dimension.
- Second layer (gcn2) maps hidden features to the final output.
- Pass adjacency matrix A and features X through both layers.
3. Running the GCN Model
Let’s test our model with some sample data:
Example Graph:
- Adjacency matrix (A) representing a simple 3-node graph.
- Feature matrix (X) with two features per node.
# Example adjacency matrix (3 nodes)
A = torch.tensor([[1, 1, 0],
[1, 1, 1],
[0, 1, 1]], dtype=torch.float32)
# Example feature matrix (3 nodes, 2 features)
X = torch.tensor([[1, 2],
[3, 4],
[5, 6]], dtype=torch.float32)
# Define the model
gcn = GCN(input_dim=2, hidden_dim=4, output_dim=2)
# Forward pass
output = gcn(A, X)
print("Final GCN Output:\n", output)6. Step-by-Step Execution
Let’s walk through what happens when we execute gcn(A, X):
- Compute A^ (Normalized Adjacency Matrix)
- Compute the degree matrix D.
- Compute D^(-1/2).
- Normalize A to get A^.
2. First GCN Layer (gcn1)
- Compute H1 = ReLU(A^ X W1) where W1 is the weight matrix of the first layer.
3. Second GCN Layer (gcn2)
- Compute H2 = ReLU(A^ H1 W2) where W2 is the weight matrix of the second layer.
4. Final Output
- H2 is returned as the final node representations.
Conclusion
In this lesson, we implemented a simple Graph Convolutional Network (GCN) in PyTorch. We followed the mathematical formula introduced in the previous lesson and broke it down into:
✔️ Computing the degree matrix D.
✔️ Computing the normalized adjacency matrix A-hat(A^).
✔️ Implementing a GCN layer.
✔️ Defining a two-layer GCN model.
In the next lesson, we will train this model on real graph data! 🚀
'Pytorch Beginner' 카테고리의 다른 글
| threading_001: Introduction to Python Threads (0) | 2025.02.09 |
|---|---|
| PyTorch_001_Building a Fully Connected Neural Network (1) | 2024.12.23 |